Super Segments and Edge Flags Simple API Approach
Super segments are collections of users that are targeted by data from any external source.
This means that users and their data can be “imported” into DevCycle for targeting in experiments or features by making use of EdgeDB.
This guide will outline how to insert data into DevCycle’s EdgeDB and then use it for targeting.
To demonstrate this most simply with no SDK installations necessary, we will use simple API calls from Postman.
Saving Data to EdgeDB from anywhere
First, enable EdgeDB in your project’s settings.
![Project Settings]Now, let's save some data to EdgeDB.
To do this, we’ll be following the EdgeDB docs from the Bucketing API.
In this case, we will update a user simply called “example_user”
We will also supply some custom data. Let's use the example of the concept of a cohort of special users you’d like to create. So we can pass that data as custom data:
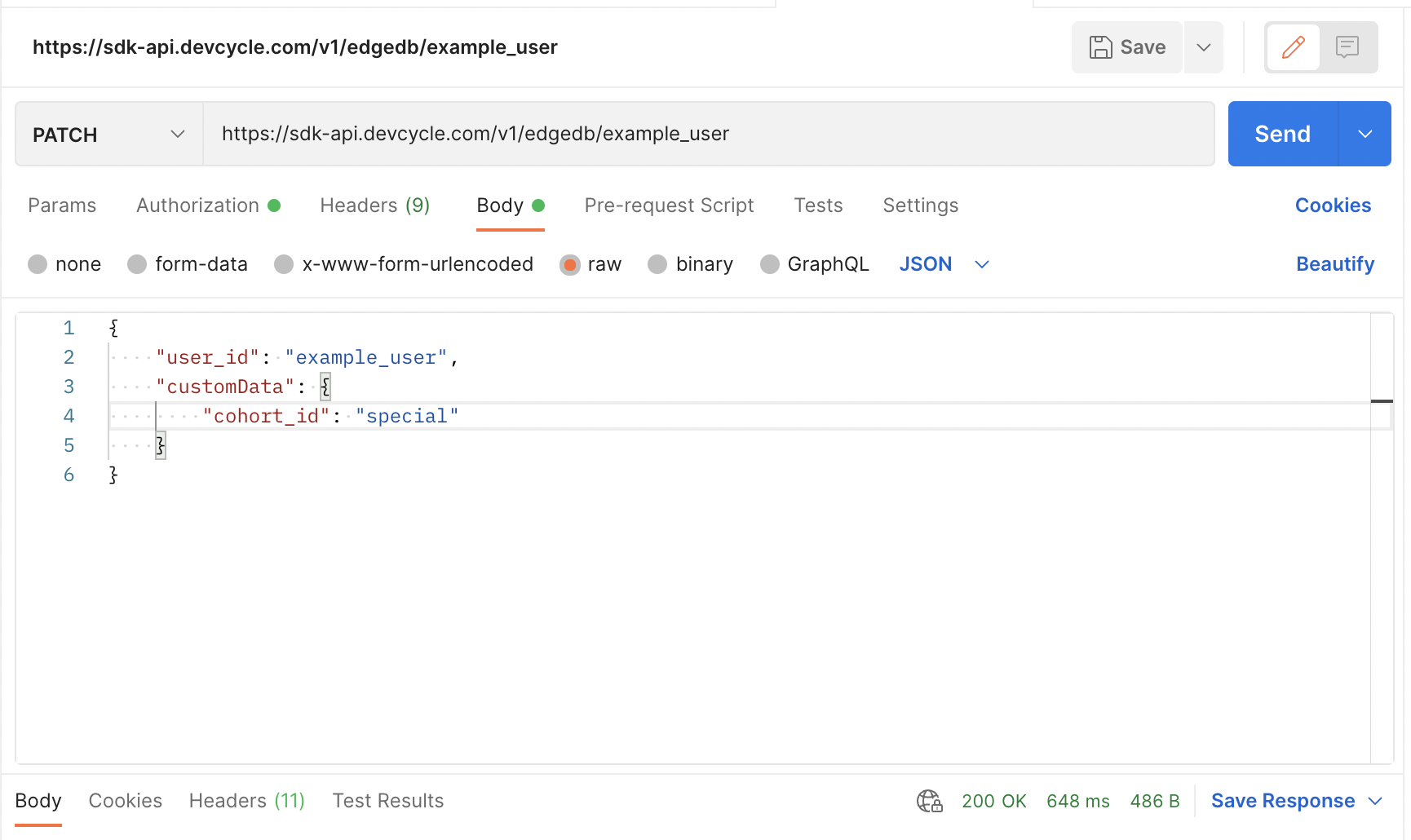
To test it yourself, here is the data:
{
"user_id": "example_user",
"customData": {
"cohort_id": "special"
}
}
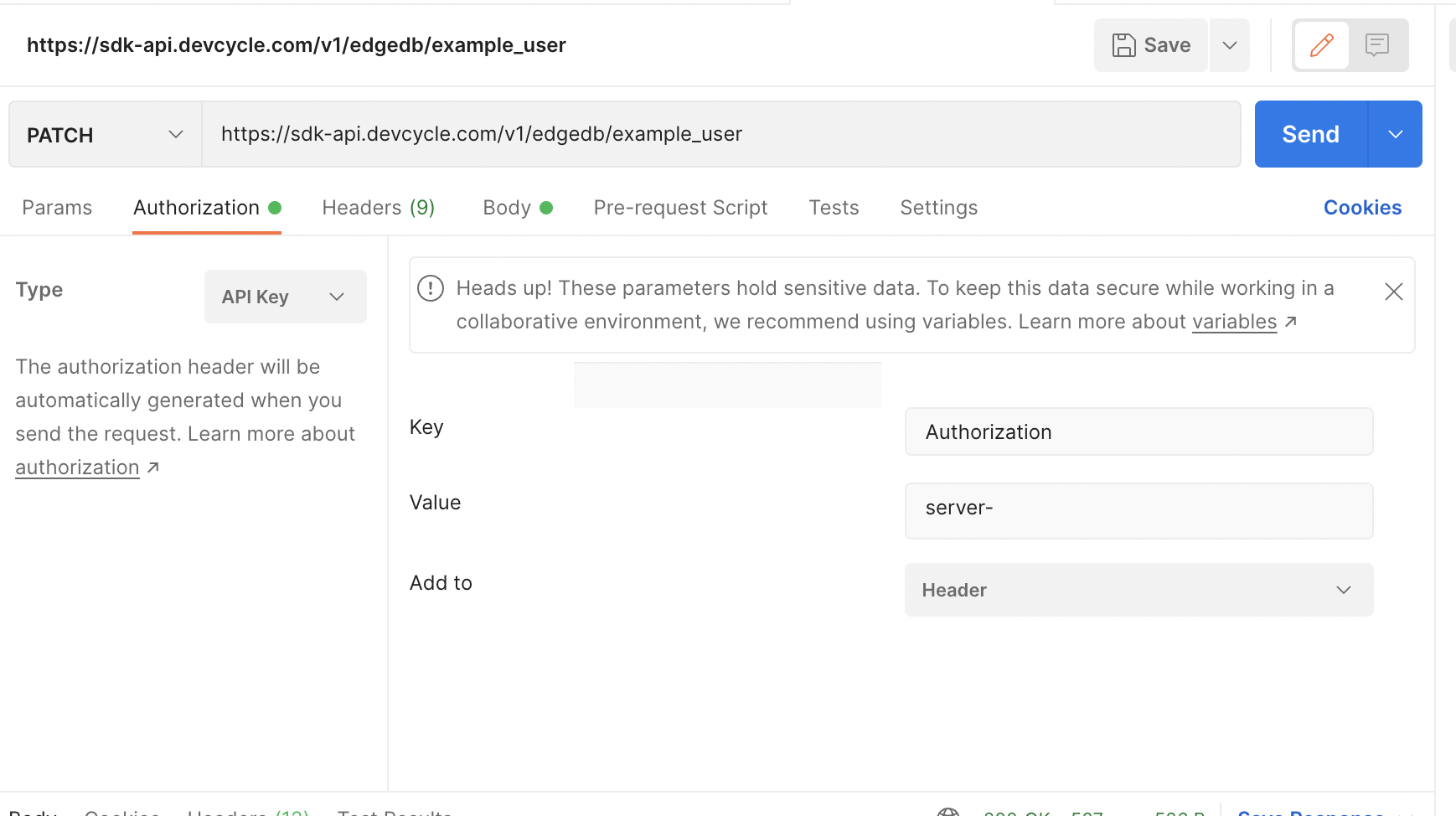
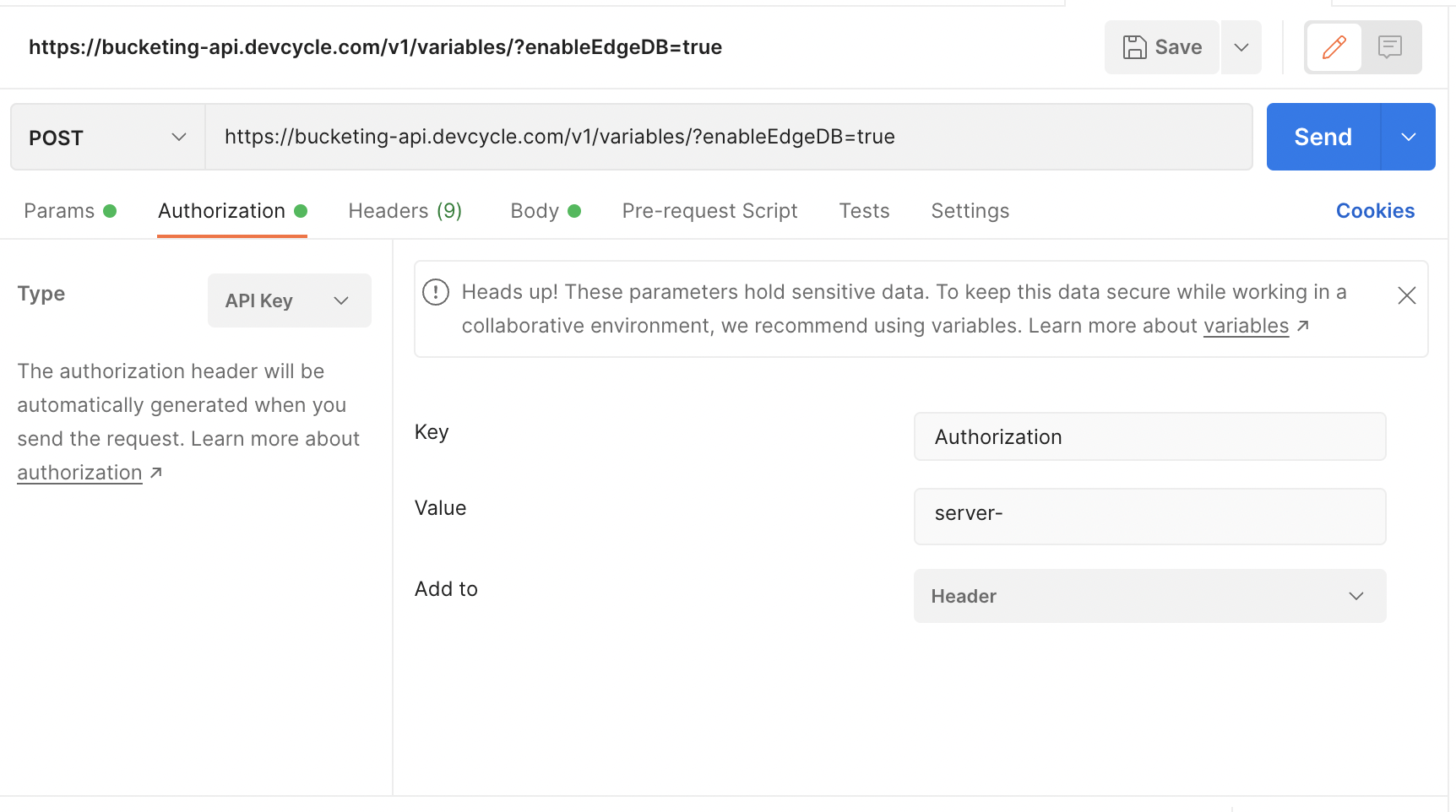
Next, we need to supply the auth. Switch to the authorization tab and change the type to API Key.
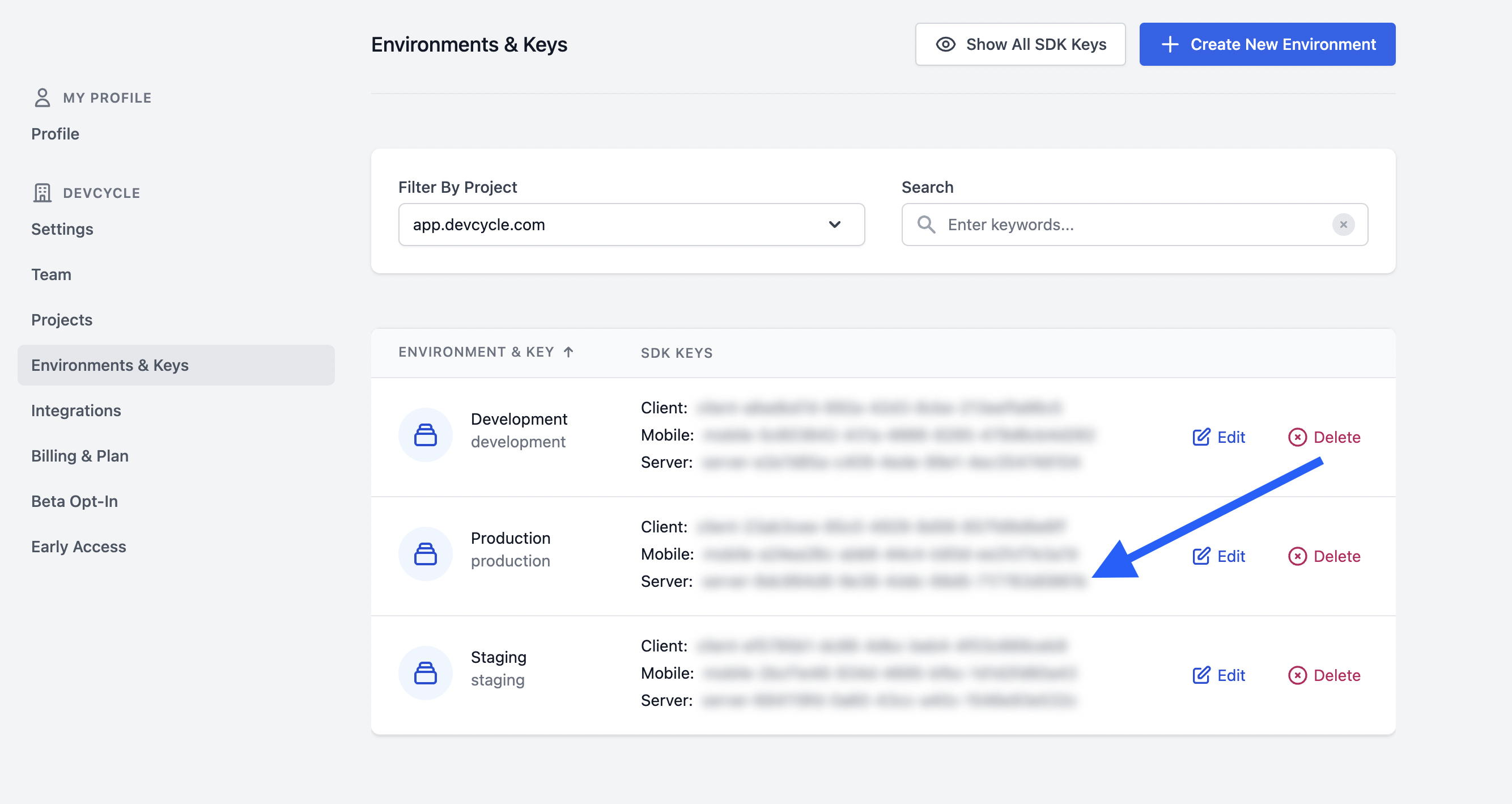
For the “Value”, supply the server SDK key found in your environments & keys tab.
For example, your production key might be here:
Rather than using postman, you could simply use a cURL request to do all of this (supplying your server SDK key)
curl --location --request PATCH 'https://sdk-api.devcycle.com/v1/edgedb/example_user' \
--header 'Authorization: <DEVCYCLE_SERVER_SDK_KEY>' \
--header 'Content-Type: application/json' \
--data-raw '{
"user_id": "example_user",
"customData": {
"cohort_id": "special"
}
}'
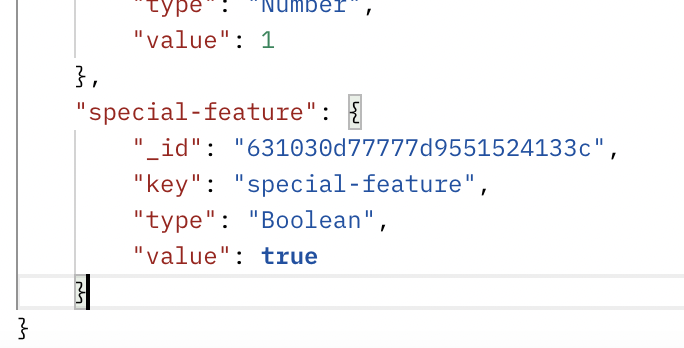
After it runs you should receive the following message:
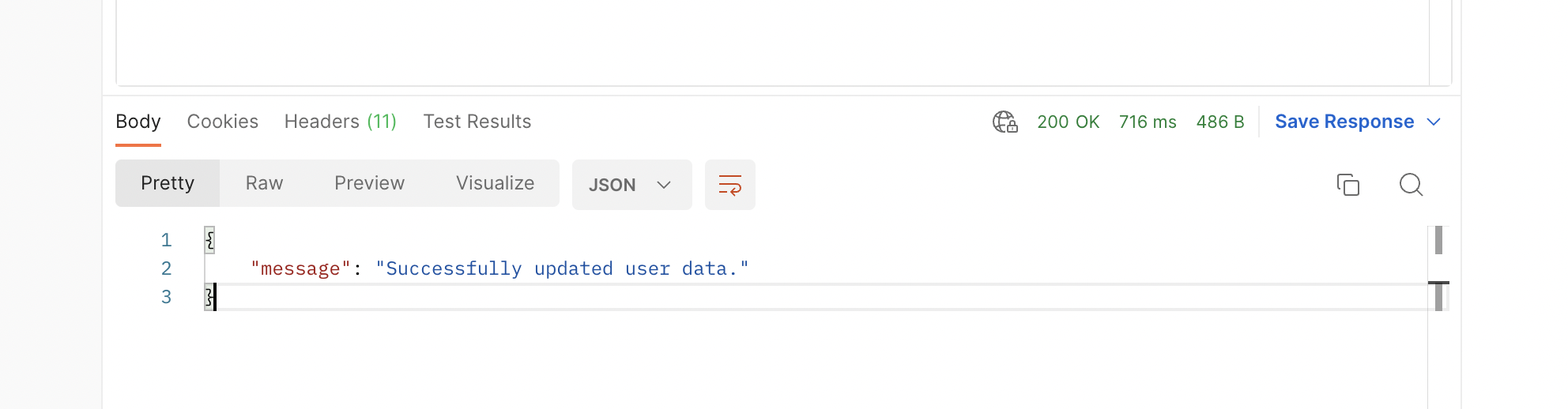
Using the data to target a DevCycle feature.
Now that we’ve got data in EdgeDB, it can be used for targeting in any feature within DevCycle.
Any data saved to EdgeDB is considered a “Custom Property” within DevCycle and can be targeted by simply adding that same property in the dashboard. To find out more about Custom Properties, read here
To use the postman data from above, simply create a new custom property in the dashboard (if it does not already exist):
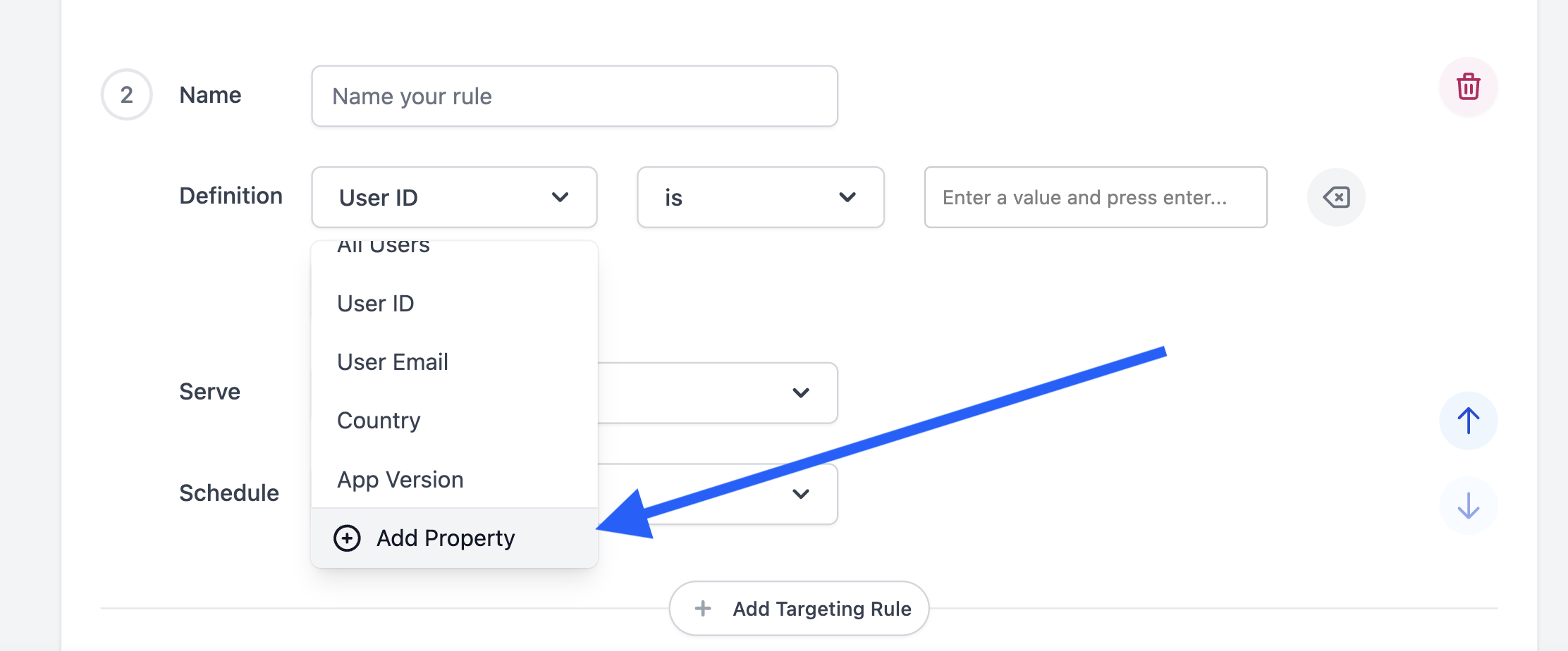
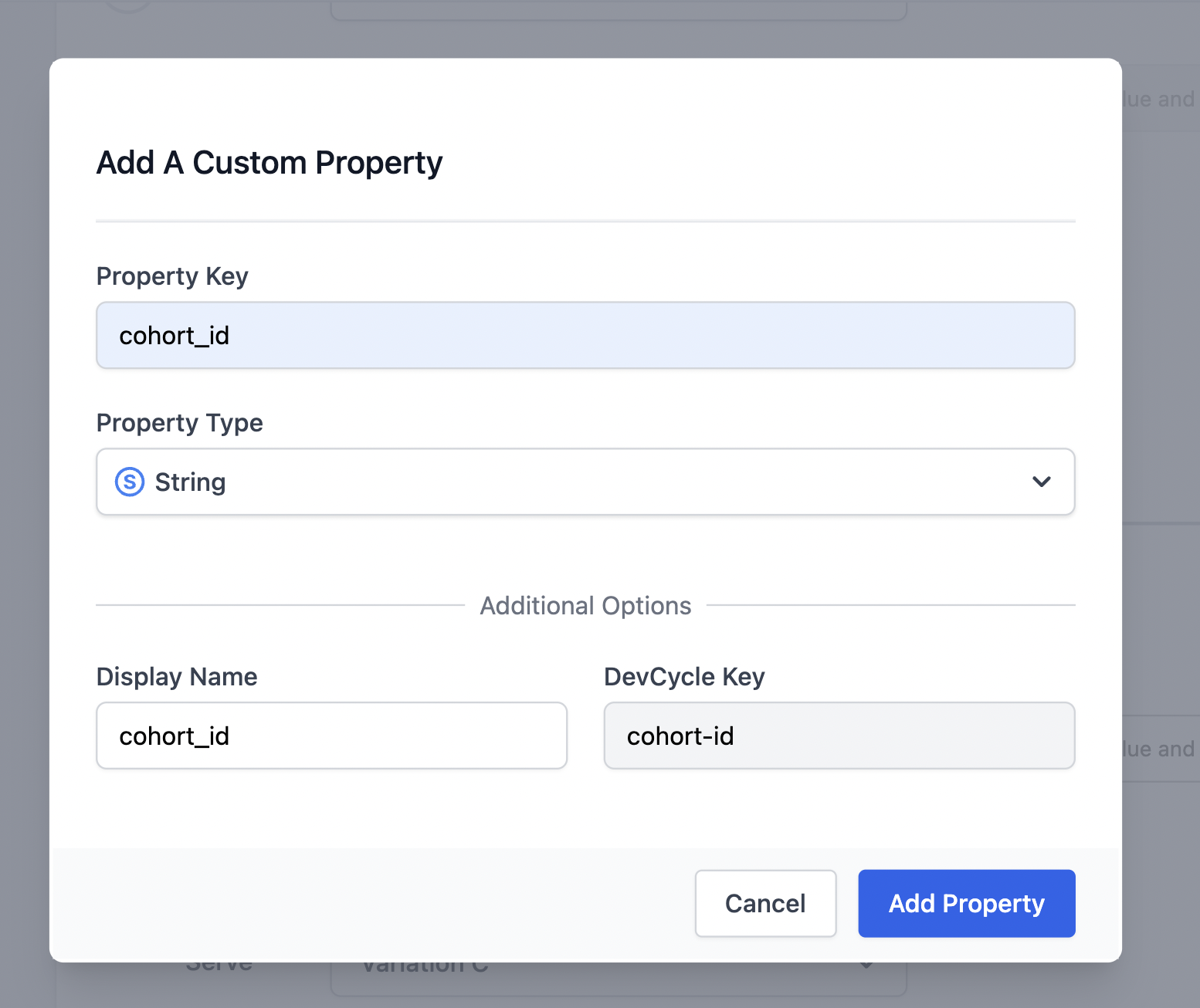
Given that we named the custom data key “cohort id”, let's create that property in our project.
And then we want to target the “special” users as we set up above.
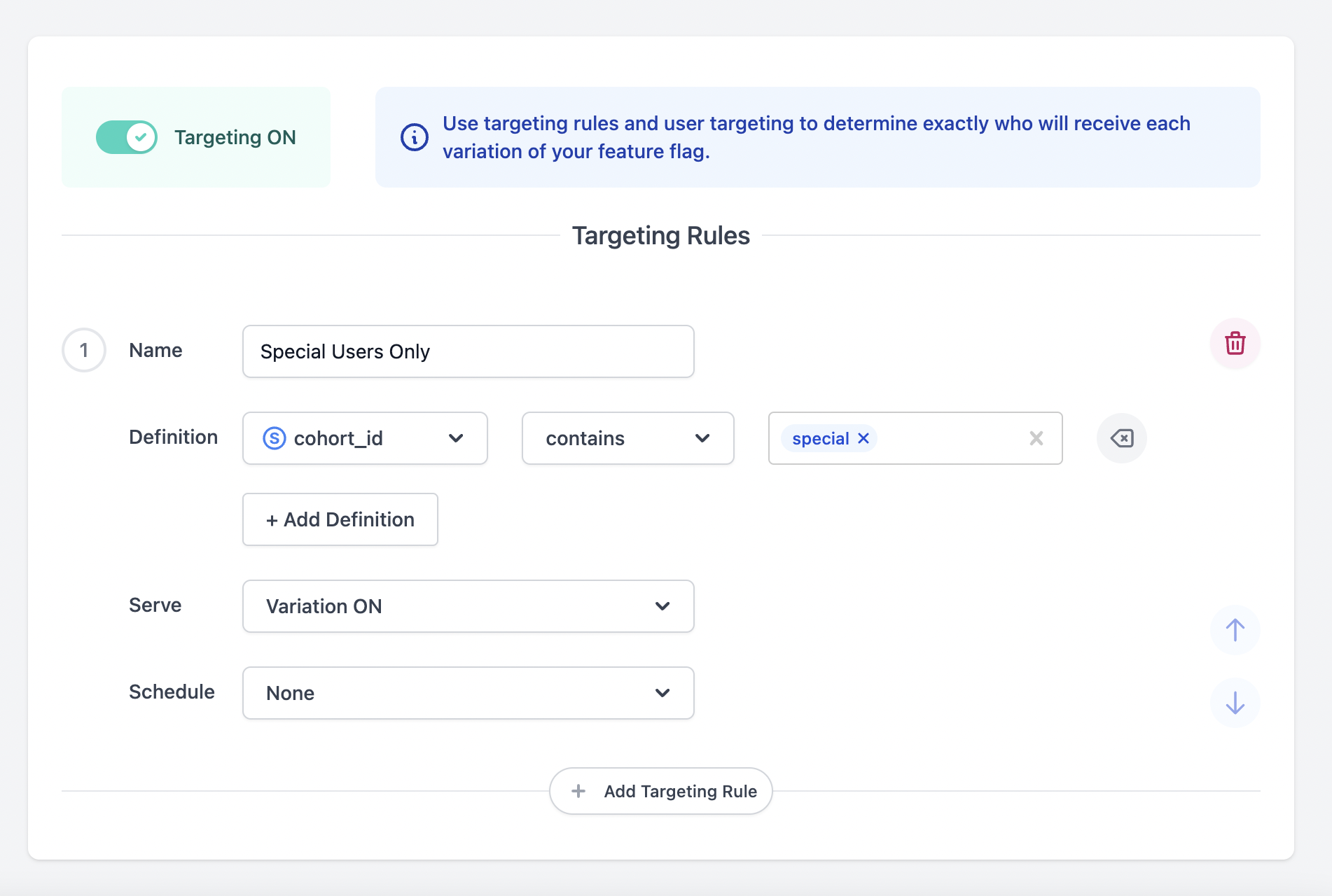
Enable this feature for your environment, and save it, and now we can test for this user’s features using the get variables feature in the Bucketing API
One thing to note is that there must be an enableEdgeDB=true flag
With the usage of EdgeDB, the user ID should have the custom data of “cohort_id:”special user” so we should only need to supply the user_id to the API and the user should receive the feature specified, as EdgeDB has the requisite info.
So we set it up like so:
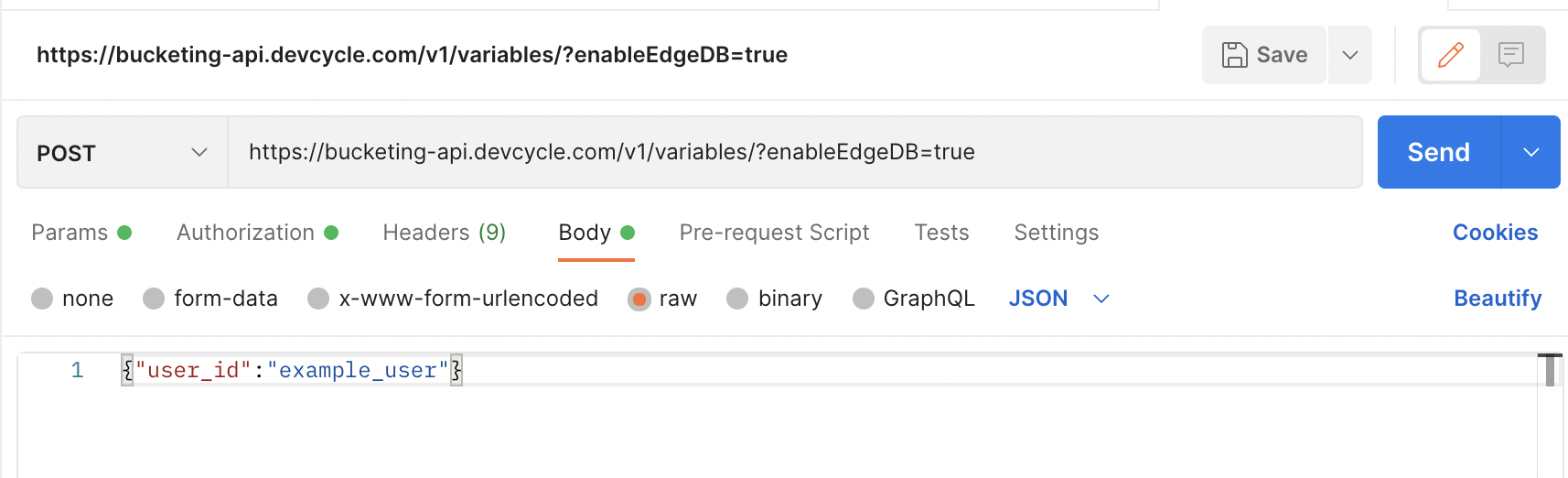
Ensure the authorization is set up with your server SDK key like above:
cURL
curl --location --request POST 'https://bucketing-api.devcycle.com/v1/variables/?enableEdgeDB=true' \
--header 'Authorization: <Your-Server-SDK-Key>' \
--header 'Content-Type: application/json' \
--data-raw '{"user_id":"example_user"}'
After running it: Voila! We receive the special feature which requires custom properties to target, without sending it in the request! It is successfully getting the data from EdgeDB: