EdgeDB and Stored Custom Properties
EdgeDB is a lightning-fast, globally replicated edge storage tool that allows you to store information about your users for future use in Targeting Rules. For example, you can set a custom property when a user performs a key action in your application, and then target based on that property in the future without having to continuously provide that data in the SDK.
EdgeDB is also a powerful tool for cross-platform feature flagging, where you may only have the user data available in one platform, but need to target the same user in another platform.
To learn more about EdgeDB check out the documentation for the features powered by EdgeDB below.
Stored Custom Properties
This guide will explain how to set up and use EdgeDB to target users using Stored Custom Properties. It will also discuss some use cases to help you determine where to implement EdgeDB in your project.
Prerequisites
To complete this guide, you will need a proficient understanding of the following DevCycle concepts:
- Identifying users within an SDK
- Targeting Rules
- Custom Properties
Setup
EdgeDB is enabled at the project level. To enable EdgeDB for your project, go to the project settings by navigating to the “Settings” tab and clicking “Projects” on the sidebar. Find your project and click edit. There you will find a dropdown to either enable or disable EdgeDB.
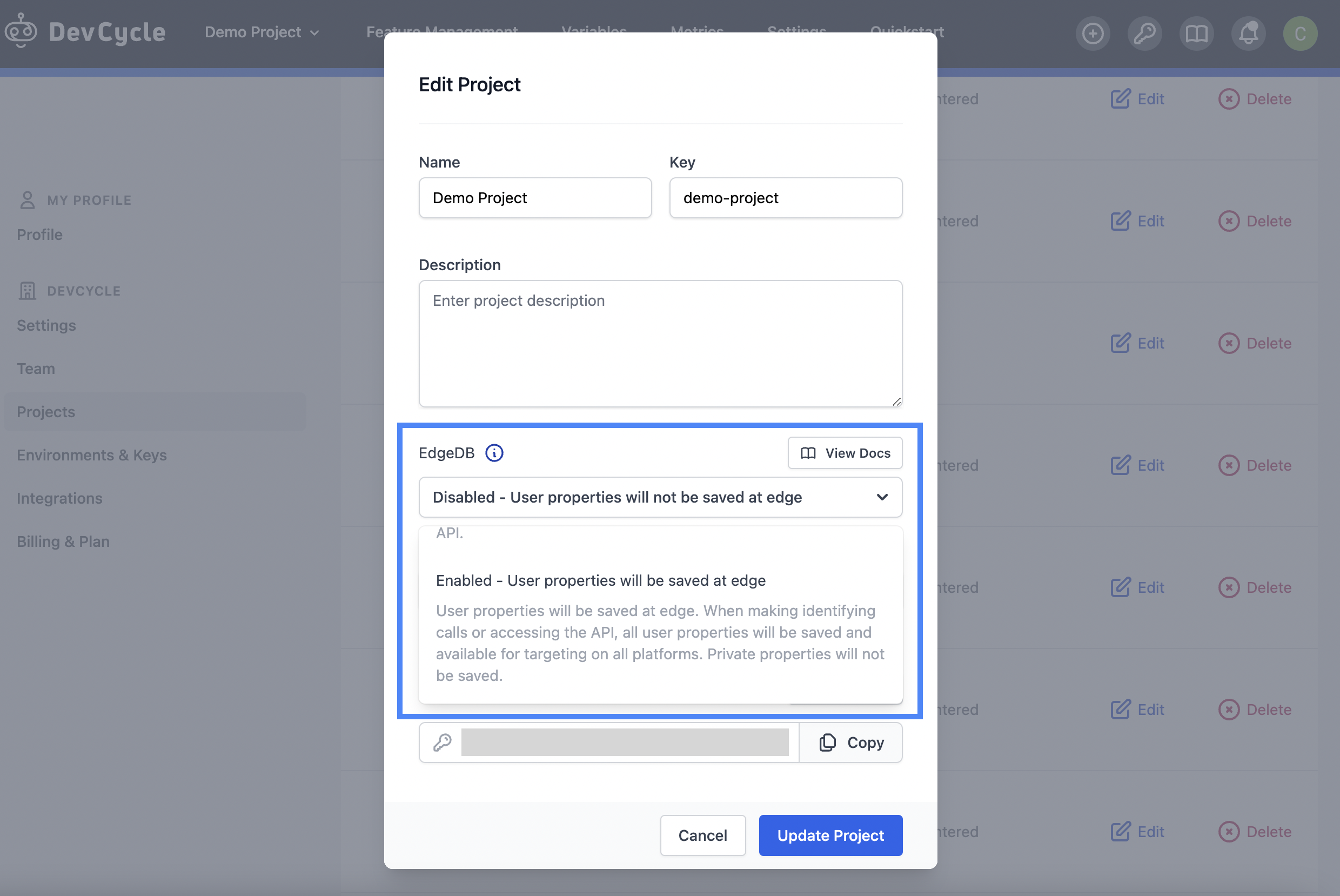
Once EdgeDB is enabled in your project, you must turn on EdgeDB mode for the SDK within your code. To do so, pass in the enableEdgeDB option and set it to true. This will look different depending on the SDK you are using. You can view our list of supported SDKs here for a specific example of how to enable EdgeDB for your SDK.
Example Usage
Let’s say you have set a Targeting Rule that targets users by a custom property called pricingPlan. We can use EdgeDB to store the user's plan for future use. To set the pricingPlan, pass in the custom property when identifying the user, in addition to the enableEdgeDB option. Note: The following example uses the JavaScript SDK.
const user = {
user_id: 'demo_user',
customData: {
pricingPlan: 'premium',
},
}
const options = {
enableEdgeDB: true,
}
const devcycleClient = initialize('ENV_KEY', user, options)
Once the data is sent to EdgeDB, you no longer need to specify it the next time the user logs in, even if it is from a different platform. Simply identify the user by user_id; in this case, it’s 'demo_user'. The targeting rules will then use the data stored on EdgeDB for 'demo_user'.
const user = {
user_id: 'demo_user',
}
devcycleClient.identifyUser(user)
In the example above, 'demo_user' will still receive the features based on their premium Pricing Plan because the data stored in EdgeDB was used for targeting.
Rest API Usage
We are able to support updates to users using our EdgeDB Public Rest API. The docs for it can be found here.
You are able to use this to update stored user custom data, and be able to use that data for segmenting in the SDKs without having to explicitly pass all of the data when identifyUser is called.
curl --location --request PATCH 'https://sdk-api.devcycle.com/v1/edgedb/my-user' \
--header 'Authorization: <YOUR-CLIENT-KEY>' \
--header 'Content-Type: application/json' \
--data-raw '{
"user_id": "my-user",
"customData": {
"amountSpent": 50
}
}'
This will make the custom data amountSpent available to segment on when identifying that same user in the SDKs without having to actually pass in the custom data. The only required piece of data is user_id.
SDK Usage
For specific documentation on how to use Edge Flags with each SDK
Client SDKs
Server SDKs
Data stored in EdgeDB is only used for user segmenting (targeting rules), so EdgeDB won’t return that data to the SDK.
In the second block of code, if we tried to access devcycleClient.user.customData.pricingPlan, it will be undefined. This does not mean the data is not in EdgeDB; it is simply because EdgeDB data is not returned to the SDK itself. However, the data will still be used for the targeting rules that were configured in the dashboard.
Keep user data on the server; feature flag on the client.
Use Cases
There are several scenarios where EdgeDB��’s data synchronization can be useful. The following list can give you some ideas about when to implement EdgeDB.
Storing complex facets or decisions about a user. There are often complex properties describing a user which are not easily retrieved or derived on each call to the SDK. For example, a data analysis system may want to categorize users a certain way based on many factors, or an application may want to record that a user performed an action in real time. EdgeDB allows you to store this information when it is available and use it later for targeting.
Storing data for cross-channel applications. When you store information in EdgeDB, you can use it as targeting data regardless of the channel in use (mobile, web, OTT, IoT). This allows you to keep a consistent user experience across platforms.
Improving customer profiles in a microservices environment. In a microservices environment, many different services are used to gather customer information. As a result, getting a complete picture of the customer may require complex data pipelines. In contrast, EdgeDB allows you to store information all in one place, no matter the source of the data.
Maintaining sessions in a serverless environment. Serverless environments can make it difficult to store session information, as data is transient. With DevCycle, you can send session information to EdgeDB and use it as targeting data whenever you need it.
Keeping Personal Identifiable Information (PII) safe from the client-side application. With EdgeDB, you no longer need to repeatedly send customer data from web apps, providing an added layer of security.
Minimizing your payload size. EdgeDB is useful when you have user objects with lots of data. Instead of sending cumbersome payload requests every time, with EdgeDB you only need to send the user_id and any new data.
Summary
In this guide we explored:
- how to enable EdgeDB for your project
- how to implement EdgeDB in your code
- some use cases on how EdgeDB can improve efficiency and privacy within your apps